Mastering Database Normalisation
Introduction to Relational Database Modeling

Working as an online tutor for the Bachelor of Computer Science Degree from Goldsmiths, University of London on the Coursera platform. This is the first undergraduate degree programme available on Coursera, one of the world’s leading online education providers.
The programme has been designed to equip students to access careers in emerging technologies, providing opportunities for students to study machine learning, data science, virtual reality, game development and web programming to meet the needs of career changers in industry as well as those taking their first steps into the innovative computer science field.
This tutorial aims to explore and explain the essential steps involved in database normalisation. We will delve into the core concepts, principles, and techniques of this process, providing a comprehensive understanding of its importance and benefits. By the end of this tutorial, you should have a clear grasp of the fundamentals of database normalisation and be able to apply them effectively in practical scenarios.
Using a University Database as our guide. You will learn the importance of structuring a database efficiently to eliminate redundancy and ensure data integrity. We will start with a basic understanding of relational database modelling and then dive into the practical application of normalising data step by step.
Normalisation is a technique used to organize data in a database to reduce redundancy and improve data integrity. Redundant data can lead to data anomalies, which are errors in the data that can occur when data is inserted, updated, or deleted.
By the end of this tutorial, you will be well-versed in the concepts of the First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), and beyond.
Introduction to Relational Database Modeling
Before we delve into normalisation, let's understand what a relational database is. A relational database is a collection of data items organised as a set of formally described tables (relations) from which data can be accessed or reassembled in many different ways without having to reorganize the database tables. The key concept here is the 'relation' or 'table'. Each table contains data about a specific object or entity, such as a student or a course.
In database design, an entity typically refers to a thing or concept that can be distinctly identified. An entity has a set of properties, and each instance of an entity has a unique value for at least one property (a unique identifier or primary key). In the context of our university database, entities would be recognisable concepts such as students, courses, and professors.
The Need for Normalization
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. The ultimate goal is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
The University Database Scenario
Imagine a university that keeps track of students, courses, and professors in a single, unnormalised table. This table includes student names, course titles, professor names, and enrollment dates. The issues with this approach are manifold - data redundancy, potential for inconsistency, and difficulty in maintaining the data.
Step-by-Step Normalisation Process
First Normal Form (1NF)
1NF is about eliminating repeating groups. Ensure that there are no duplicate columns and that each cell in the table contains only a single value.
Second Normal Form (2NF)
For a table to be in 2NF, it must first be in 1NF and then it must also ensure that all non-key attributes are fully functionally dependent on the primary key.
Third Normal Form (3NF)
A table is in 3NF if it is in 2NF and all the attributes are not only fully functionally dependent on the primary key but also are non-transitively dependent on the primary key.
Boyce-Codd Normal Form (BCNF)
BCNF is an extension of 3NF. A table is in BCNF if it is in 3NF and for every one of its dependencies, X → Y, X is a super key.
Now, let's begin with the actual data and the normalisation process.
Let's start with the unnormalized data:
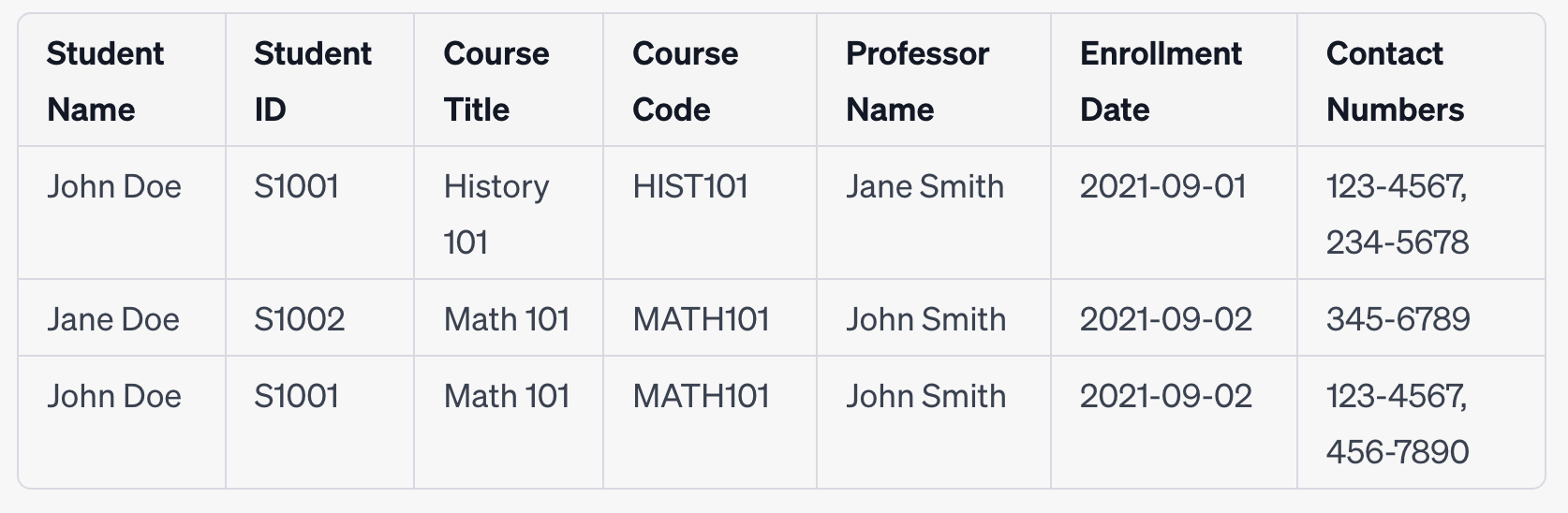
In the next part of the tutorial, we will take this data through the normalisation process, starting with 1NF.
First Normal Form (1NF)
The First Normal Form (1NF) is a foundational concept in database normalisation. It sets the stage for further normalisation steps by ensuring that the data in a table is structured in a way that enhances consistency and facilitates efficient querying. Here's a more detailed look at 1NF:
Definition and Key Principles
1NF focuses on the following key principles:
Atomicity: Each cell in a table should contain only a single value. This means that there are no multi-valued attributes or sets of values in a single cell. For instance, a cell under a column "Contact Numbers" should not contain multiple phone numbers.
Uniqueness of Rows: Each row in the table should be unique. This can be achieved by ensuring that the table has a primary key, a column, or a set of columns that uniquely identify each record in the table.
No Repeating Groups: The table should not contain repeating groups of columns. For example, a table should not have columns like "Phone1", "Phone2", or "Phone3" for storing multiple phone numbers for a single entity.
Applying 1NF to the University Database
Let's modify our unnormalized university database table to include a column that clearly violates the atomicity principle, making it a better candidate for demonstrating the application of 1NF.
Core Principles of 1NF:
Atomic Values: Each cell in a table should contain a single atomic value. This means that the value should not be a collection or a composite of multiple values.
No Repeating Groups: There should be no repeating groups of columns within a table. This means that each column should represent a distinct attribute of the data entity being stored.
Unique Column Names: Each column in a table should have a unique name to avoid ambiguity and facilitate data manipulation.
Primary Key: Every table should have a primary key, which is a unique identifier that distinguishes each row in the table.
1NF is about eliminating repeating groups. Ensure that there are no duplicate columns and that each cell in the table contains only a single value.
Original Unnormalized Table
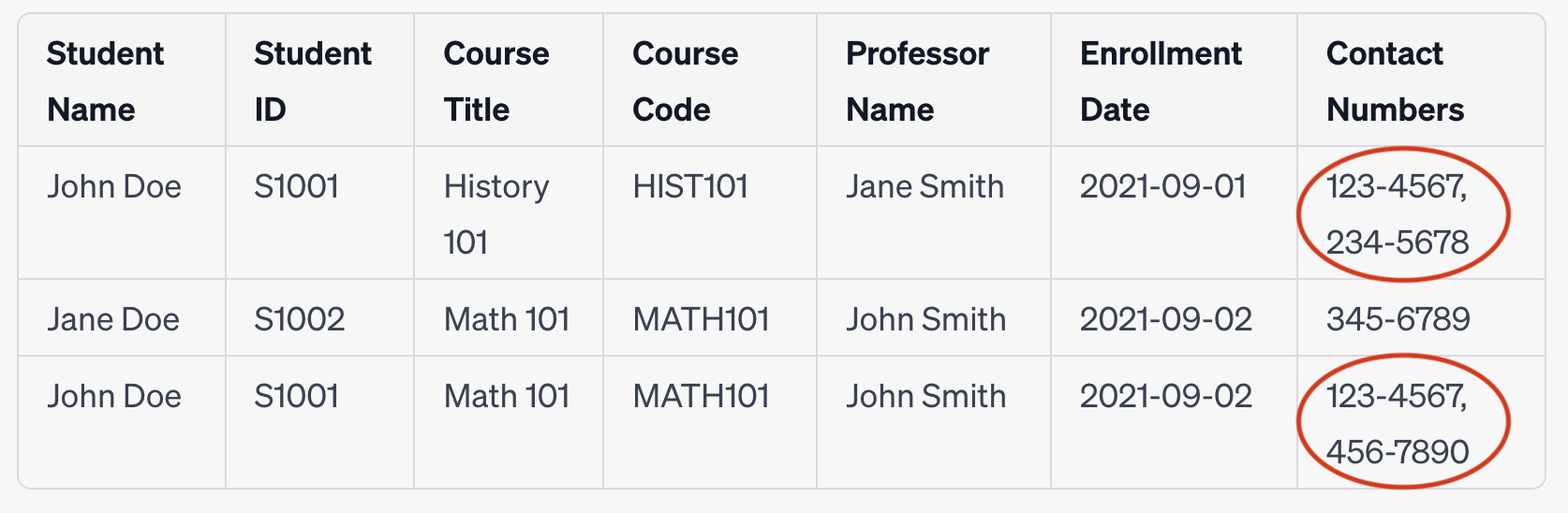
In this table, the "Contact Numbers" column contains multiple values in a single cell, which violates the atomicity principle of 1NF.
Applying 1NF
To bring this table into 1NF, we need to address the atomicity issue by ensuring that each cell contains only a single value. Here's how we can do it:
Split Multiple Values: We need to separate the multiple contact numbers into individual records. This might increase the number of rows in the table but will ensure that each cell holds only one value.
Ensure Uniqueness of Rows: We can maintain a composite primary key (Student ID, Course Code, Enrollment Date, Contact Number) to ensure each row remains unique.
Table after Applying 1NF
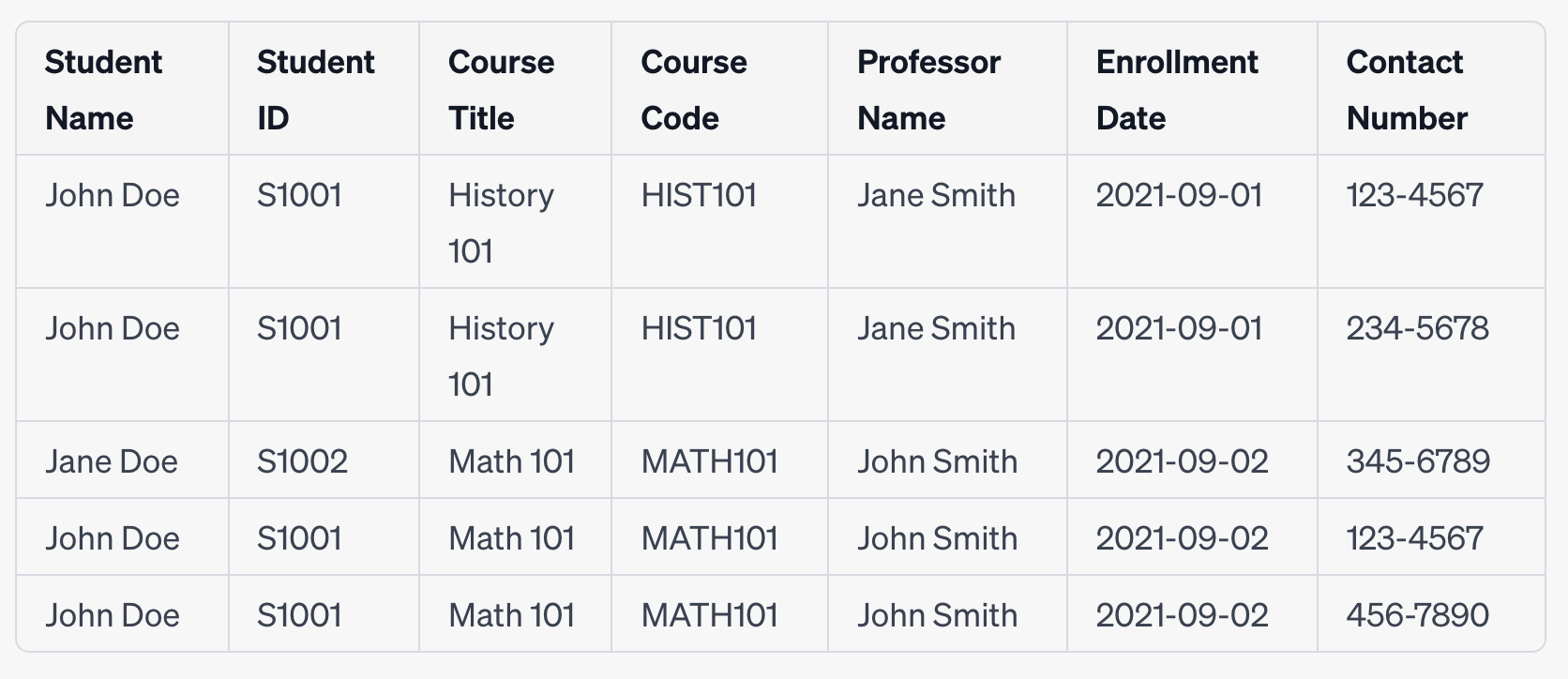
Now, each cell in the "Contact Number" column contains only a single "atomic" value, adhering to the atomicity principle of 1NF. This change makes the table more manageable and sets the foundation for further normalization steps.
Benefits of Adhering to 1NF:
Data Integrity: 1NF ensures data accuracy and consistency by eliminating redundant and contradictory information.
Efficient Data Storage: By removing repeating groups, 1NF reduces storage requirements and improves data organization.
Simplified Data Manipulation: 1NF makes it easier to perform operations on data, such as querying, filtering, and updating, as the data is structured clearly and consistently.
1NF is about eliminating repeating groups. Ensure that there are no duplicate columns and that each cell in the table contains only a single value.
Understanding Second Normal Form (2NF)
After achieving the First Normal Form (1NF), the next step in the normalisation process is to bring the database to the Second Normal Form (2NF). Let's delve into what 2NF entails and how to achieve it.
Definition and Key Principles of 2NF
A table is in 2NF if it satisfies two conditions:
It is already in 1NF: This means the table has no repeating groups, and each cell contains only a single value.
All non-key attributes are fully functionally dependent on the primary key: This means that every non-key attribute must be dependent on the entire primary key, not just a part of it. In other words, there should be no partial dependency of any column on the primary key.
Why Move from 1NF to 2NF?
The main reason to transition from 1NF to 2NF is to reduce redundancy and improve data integrity. Partial dependencies can lead to anomalies in data insertion, deletion, and update operations. By ensuring full functional dependency, 2NF helps in structuring the database more efficiently, making it easier to maintain and update.
Applying 2NF to Our 1NF Table
Let's revisit our 1NF table:
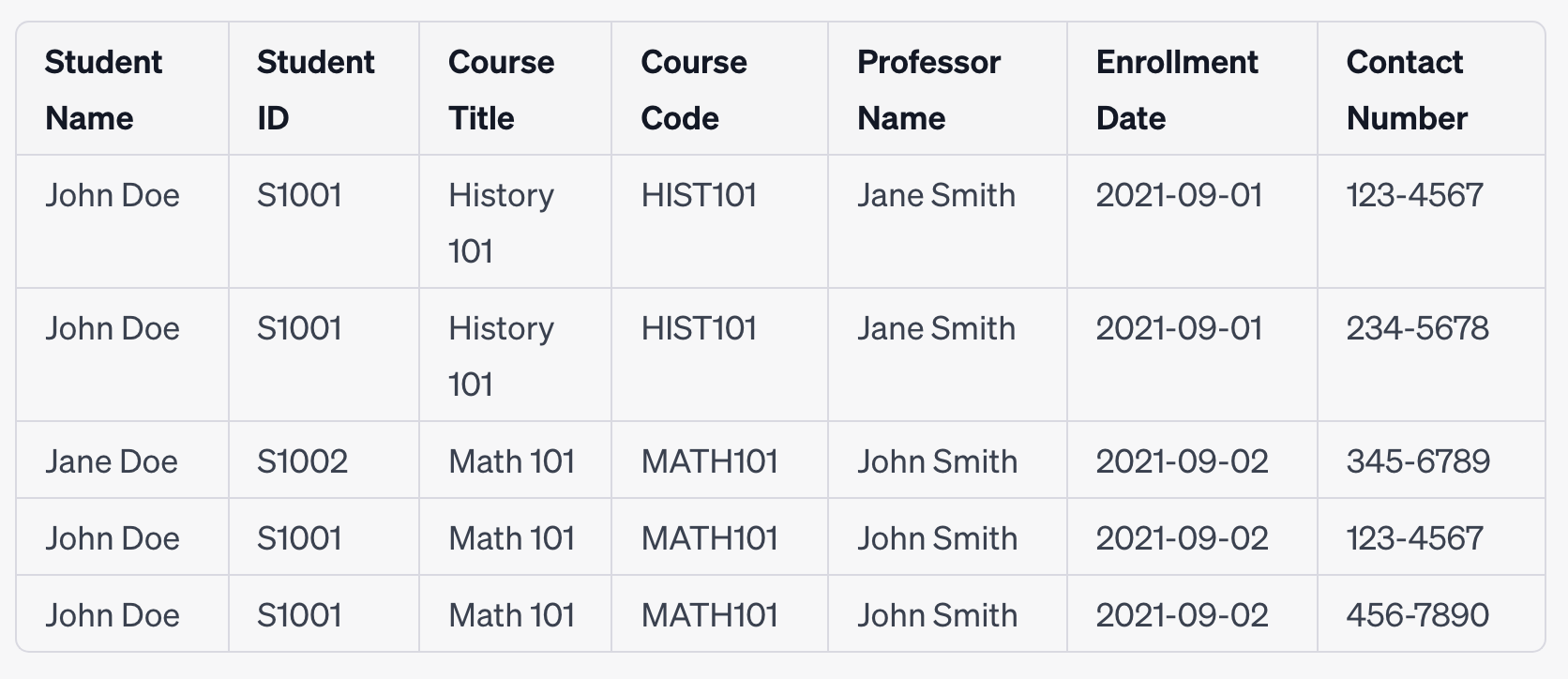
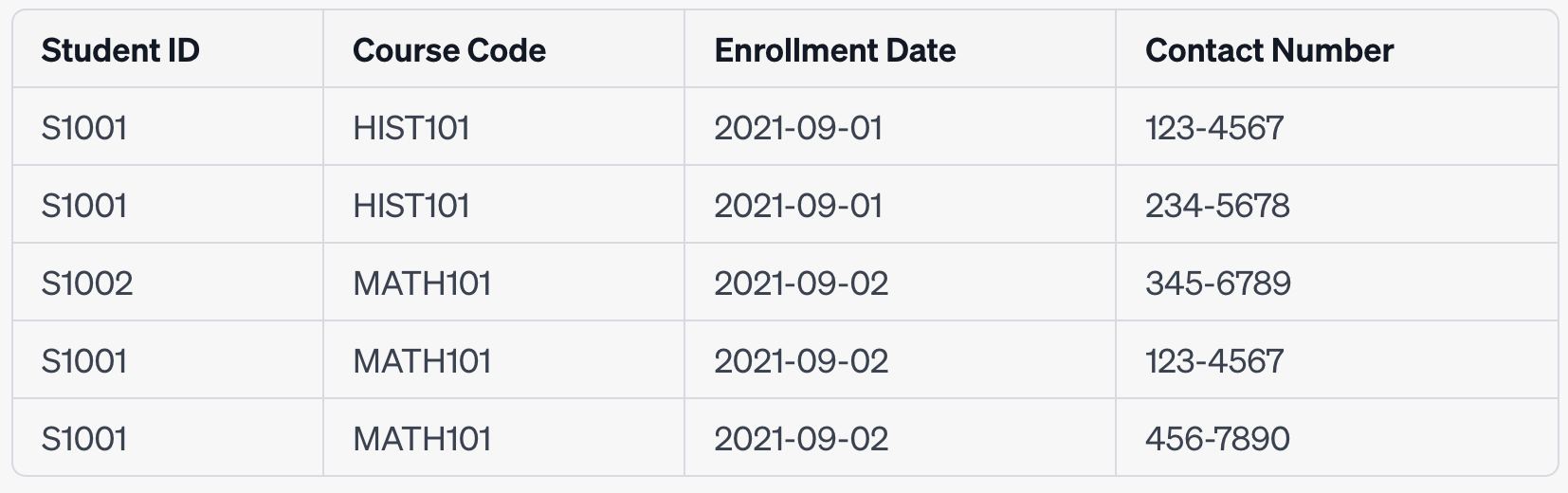
In this table, we notice that certain attributes like "Student Name", "Course Title", and "Professor Name" are not fully functionally dependent on the composite primary key (Student ID, Course Code, Enrollment Date, Contact Number). For example, "Student Name" is dependent only on "Student ID" and not on the entire primary key.
Full Functional Dependency in the 1NF Table
In our 1NF table, we have a composite primary key consisting of:
"Student ID", "Course Code", "Enrollment Date" and "Contact Number".
Full functional dependency means that all other columns in the table should be dependent on this entire composite key. However, we observe that some columns are only partially dependent on a portion of the primary key. Let's explore this with more examples:
Partial Dependencies in the Table
Student Name and Student ID:
The "Student Name" is dependent only on the "Student ID". It doesn't change based on the "Course Code" or the "Enrollment Date". This is a partial dependency because "Student Name" is related to only a part of the primary key (just "Student ID").
Course Title and Course Code:
Similarly, the "Course Title" is dependent only on the "Course Code". It doesn't vary with different "Student IDs" or "Enrollment Dates". This is another example of partial dependency.
Professor Name and Course Code:
In most cases, "Professor Name" might be associated with "Course Code", assuming one professor teaches a specific course.
Illustrating Partial Dependency with More Examples
Example 1: If "John Doe" (Student ID: S1001) enrols in another course, say "Physics 101" (Course Code: PHYS101), his name will still be "John Doe". The "Student Name" is not dependent on the "Course Code" or "Enrollment Date".
Example 2: If "History 101" (Course Code: HIST101) is taught by "Jane Smith", this fact remains true irrespective of who the student is or when they enrol. The "Professor Name" is dependent only on the "Course Code".
Example 3: If a new student, "Alice Johnson" (Student ID: S1003), enrols in "Math 101" (Course Code: MATH101), the course title "Math 101" remains the same, showing that "Course Title" is dependent only on "Course Code".
Resolving Partial Dependencies for 2NF
To resolve these partial dependencies and achieve 2NF, we need to separate the data into different tables where each non-key attribute is fully functionally dependent on the primary key of its table.
Steps to Normalize to 2NF
Identify Partial Dependencies: Look for columns that are dependent only on a part of the primary key.
Remove Partial Dependencies: Create separate tables to eliminate these partial dependencies.
Creating Separate Tables for 2NF
Student Table: Contains student-related information.
Columns: Student ID, Student Name
Primary Key: Student ID
Course Table: Contains course-related information.
Columns: Course Code, Course Title, Professor Name
Primary Key: Course Code
Enrollment Table: Contains enrollment details.
Columns: Student ID, Course Code, Enrollment Date, Contact Number
Primary Key: Composite key of Student ID, Course Code, and Enrollment Date
Resulting 2NF Tables
Student Table

Course Table

Enrollment Table
By addressing these partial dependencies, we ensure that each piece of information is stored in the most appropriate place, reducing redundancy and improving the integrity and efficiency of the database.
By restructuring the data in this way, we have successfully normalized our table to 2NF. This structure reduces redundancy and improves the overall integrity and efficiency of the database.
So to resolve these partial dependencies and achieve 2NF, we need to separate the data into different tables where each non-key attribute is fully functionally dependent on the primary key of its table. This leads to the creation of the "Student", "Course", and "Enrollment" tables as shown above.
Understanding Third Normal Form (3NF)
After achieving the Second Normal Form (2NF), the next step in database normalization is to reach the Third Normal Form (3NF). Let's explore what 3NF is and how to apply it to our database.
Definition and Key Principles
A table is in 3NF if it satisfies two main conditions:
It is already in 2NF: This means the table has no partial dependencies; all non-key attributes are fully functionally dependent on the primary key.
No Transitive Dependencies: This means that non-key attributes must not depend on other non-key attributes. In other words, every non-key attribute should be directly dependent on the primary key, not through another non-key attribute.
Why Move from 2NF to 3NF?
The primary goal of transitioning to 3NF is to eliminate transitive dependencies, which can lead to redundancies and anomalies in the database. By ensuring that all non-key attributes are directly dependent on the primary key, 3NF further improves data integrity and reduces redundancy.
Definition of Transitive Dependency
In more formal terms, a transitive dependency in a relational database occurs when the following conditions are met:
There is a functional dependency between two attributes, say A and B (A → B), meaning B is functionally dependent on A.
There is another functional dependency between B and a third attribute C (B → C).
A is a primary key or part of a primary key, and C is a non-key attribute.
In this scenario, C has a transitive dependency on A through B. This means that the value of C is indirectly dependent on the value of A, via B.
For our university, Let's consider a hypothetical scenario where "Student Name" is included in this table:

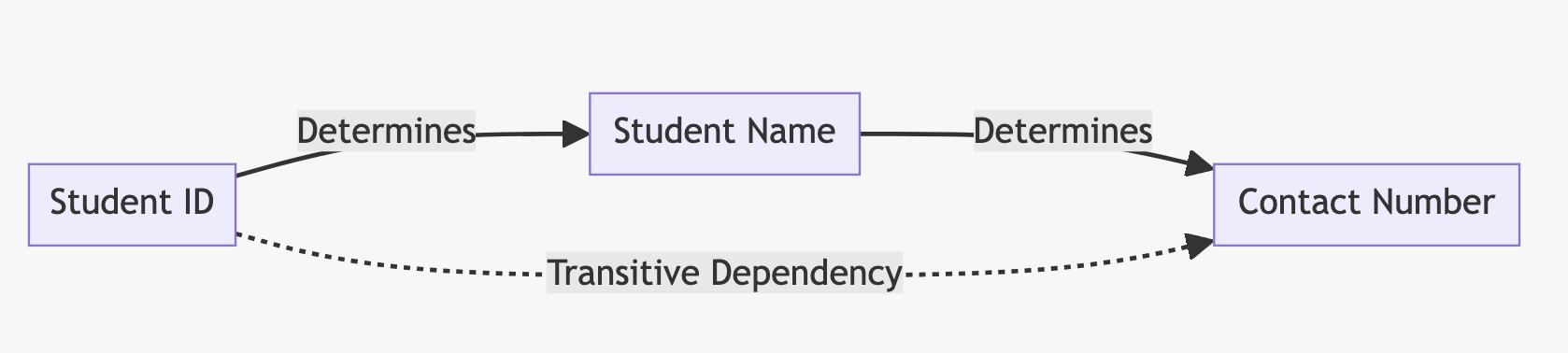
In this diagram, "Student ID" determines "Student Name", and "Student Name" determines "Contact Number". This creates a transitive dependency where "Student ID" indirectly determines "Contact Number" through "Student Name".
To illustrate this further, let's consider a hypothetical table with the following structure:

In this table:
Employee ID → Department Name (Employee ID determines the Department Name)
Department Name → Department Manager (Department Name determines the Department Manager)
Here, the Department Manager (C) is transitively dependent on the Employee ID (A) through the Department Name (B). The proper way to eliminate this transitive dependency, according to 3NF, would be to separate this information into different tables, ensuring that each non-key attribute is directly dependent on a primary key.
Applying 3NF to Our 2NF Tables
Recall our 2NF tables:
Student Table
Course Table
Enrollment Table
In these tables, let's check for transitive dependencies...
Transitive dependencies in a database context refer to a condition where a non-key attribute is dependent on another non-key attribute, which in turn is dependent on the primary key of the table. This kind of dependency implies an indirect relationship between a non-key attribute and the primary key, mediated through another non-key attribute.
In the Student Table, there are no transitive dependencies. "Student Name" is directly dependent on "Student ID".
In the Course Table, there are no transitive dependencies. Both "Course Title" and "Professor Name" are directly dependent on "Course Code".
In the Enrollment Table, there are no apparent transitive dependencies. Each attribute is directly dependent on the composite key (Student ID, Course Code, Enrollment Date).
Since there are no transitive dependencies in these tables, they are already in 3NF.
Example of Transitive Dependency (Hypothetical)
To better understand transitive dependency, let's consider another hypothetical scenario. Suppose we had an additional column in the Course Table, say "Department", which is dependent on "Course Title". This would create a transitive dependency: Course Code → Course Title → Department.
In this case, "Department" is not directly dependent on the primary key "Course Code" but is dependent through "Course Title". To resolve this, we would need to create a separate table for "Departments".
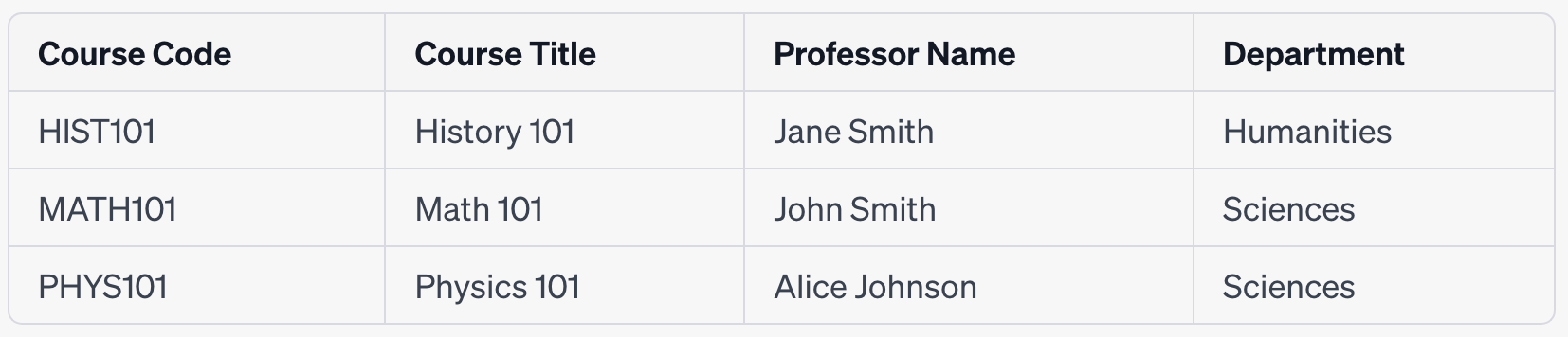
In this table:
Course Code determines Course Title (Course Code → Course Title).
Course Title determines Department (Course Title → Department).
Here, Department is transitively dependent on Course Code through Course Title. This is because the department to which a course belongs is determined by the course title, which in turn is determined by the course code.
Resolving Transitive Dependency
To resolve this transitive dependency and achieve 3NF, we need to remove the transitive dependency by creating a separate table for departments. The revised structure would look like this:
Course Table (Revised)

Department Table
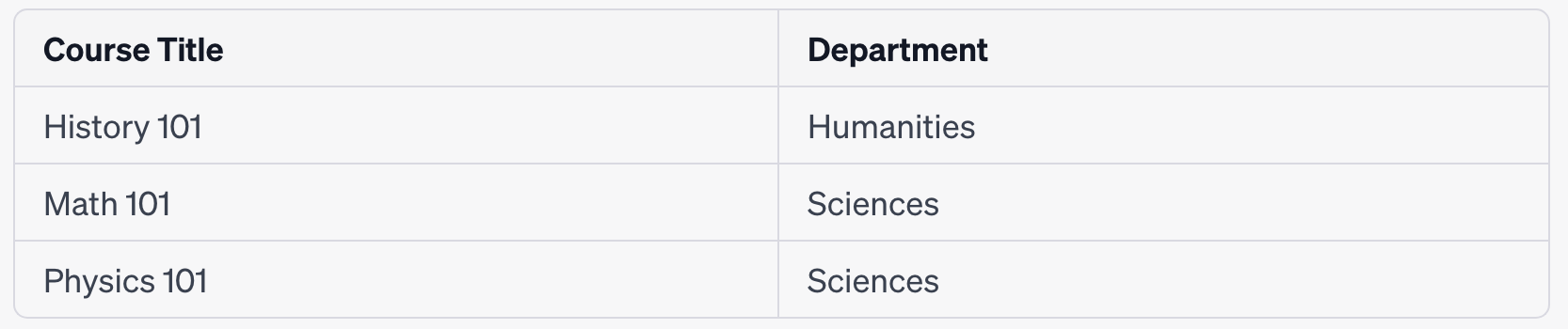
In this revised structure:
The Course Table no longer has the transitive dependency. Each attribute in this table is directly dependent on the primary key, "Course Code".
The Department Table captures the relationship between the course titles and their respective departments.
By separating the information into two tables, we have effectively normalized the database to 3NF, eliminating the transitive dependency and improving the database's overall structure and integrity.
Benefits of 3NF
Reduces Redundancy: By eliminating transitive dependencies, 3NF reduces data redundancy, making the database more efficient.
Improves Data Integrity: It ensures that updates, deletions, and insertions are less likely to introduce inconsistencies.
Simplifies Database Design: A well-normalized database is easier to maintain and modify.
In summary, achieving 3NF is about ensuring that all non-key attributes in a table are directly dependent on the primary key and not on other non-key attributes. This step is crucial for maintaining a streamlined and efficient database structure.
Let's revisit the three tables from our university database example, which we previously normalized to the Third Normal Form (3NF). We'll then explore the possibility of advancing these tables to the Boyce-Codd Normal Form (BCNF).
University Database Tables in 3NF
Student Table
Course Table
Enrollment Table
Advancing to Boyce-Codd Normal Form (BCNF)
BCNF is a stricter form of the Third Normal Form. A table is in BCNF if it is in 3NF and for every one of its non-trivial functional dependencies, X → Y, X is a superkey. A superkey is a set of attributes that uniquely identifies a row in a table.
Analyzing Tables for BCNF
Student Table:
- The primary key is "Student ID", which uniquely identifies each student. There are no non-trivial functional dependencies where the left-hand side is not a superkey. Therefore, this table is already in BCNF.
Course Table:
- The primary key is "Course Code", which uniquely identifies each course. Similar to the Student Table, there are no non-trivial functional dependencies that violate BCNF. Hence, this table is also in BCNF.
Enrollment Table:
- A potential primary key could be the combination of "Student ID", "Course Code", and "Enrollment Date". This composite key uniquely identifies each record. If there are no other functional dependencies where the left-hand side is not a superkey, this table would also be in BCNF.
Conclusion
Based on the provided information, all three tables (Student, Course, and Enrollment) appear to be in BCNF, as there are no non-trivial functional dependencies that violate the conditions of BCNF. Each table has a primary key or a composite key that uniquely identifies its records, and there are no attributes functionally dependent on anything other than these keys.
Resources




